
ICML 2025聚光灯
栏目:企业动态 发布时间:2025-05-23 10:21
“三点电荷 + q,-2q和 + 3q同样放置,其向量最能描述作用于 + Q电荷的净功率...
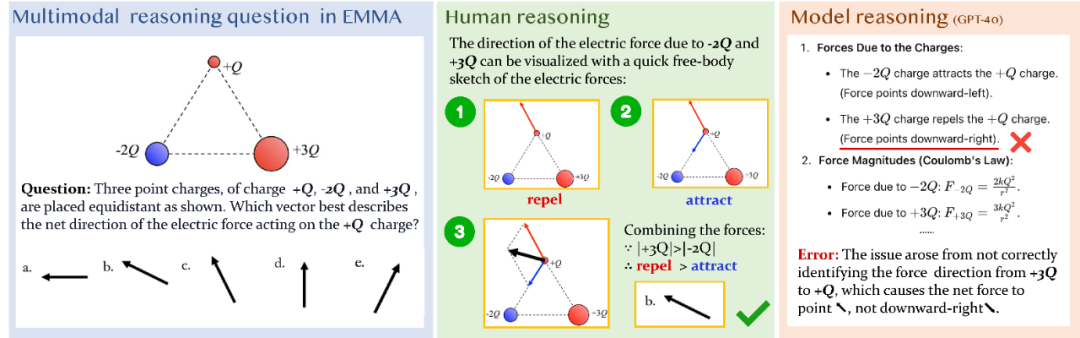 “三点电荷 + q,-2q和 + 3q平等放置。哪个向量最能描述作用在 + Q电荷上的净功率的方向?”解决此问题时,我们可以通过绘制力量分析的草图来轻松解决它。但是,即使是GPT-4O等先进的多模式大型语言模型,也可能会错误地判断拒绝的方向:在理解“同性拒绝”的基本物理原理时(例如,错误地判断否定 +3Q的 +3Q方向为 +Q的 +Q作为下部右侧而不是右上左侧)。看似简单的物理问题揭示了多模型模型的“致命缺陷”:当前的MLLM仍然无法产生复杂的多模式推理,需要将深度透视和文本整合在一起!艾玛(Emma)的基准发射了新研究,就像是“恶魔镜”,表明即使是领先的MLLM也有重大的缺点。目前,这项研究已被接受为ICML 2025聚光灯,并且代码数据完全O笔资源!标题:MLLM可以引起多模式吗?艾玛:改进的多模式推理基准纸链接: https://www.arxiv.org/pdf/2501.054444444444444444444444444444444444444444444444444444444444444444444444444444; “ https://huggingface.co/datasets/luckychao/emma部门:孙子Yat-sen大学电子科学技术大学,华盛顿大学,微软大学,中文大学,目前具有EMMA中的许多模型/方法,在上面证明,它已被证明是多种研究和研究的能力,并且已经发现了研究的模型。 O3/O4-Mini模型可以在人类专家身后捕获20%以上的人!ual thinking and spatial simulation" to efficiently find the path-solving path. In sharp contrast, models (like the O3) rely on detailed, structured text steps for reasoning. This difference highlights that current MLLMs tend to use their strong language logic capabilities to process when processing multimodal information, nGorgeously show like human, visual centered on intuitive perspective and flexible and excellent problem solving techniques. Emma: In-depth consideration有机地结合文本和图像信息和进行音乐会推理的多模式的理论是人类智力的基本能力,如果多模式模型真正具有这种深层的水平,那么多模型的多模式推理能力仍然缺乏系统的限制和唯一的用文字。视觉感知“而不是” visual reasoning" to solve the problem. Difficult to comprehensively measure model's ability to combine visual and linguistic imFormation in complex activities, so it is impossible to effectively evaluate the true understanding of multimodal and reasoning level. To meet this challenge, researchers suggested Emma, an enhanced benchmark designed to review native multimodal reasoning for MLLMs in four major fields: mathematics, physics, chemistry and code, as shown in the figure below. EMMA activities require advanced cross-modal reasoning, which cannot be solved by thinking independently in a single mode, providing a more stringent and comprehensive "touchstone" for MLLMS reasoning capabilities. Emma is not just a new review, this is a carefully designed set of "testing questions" aimed at comprehensively reviewing the capabilities of MLLMs in the following aspects: real multimodal fusIon: Emma's main criterion is to test if the model can perform "true"多模式推理应通过视觉信息(例如图表,示意图,化学结构,代码纪念)和文本信息(问题描述,逻辑条件)深入解决问题,从而测试模型无缝移动和在不同模式之间进行深层集成的能力。严重的跨学科挑战:为了完成对将军的一般能力的分析,艾玛涵盖了科学和工程的四个主要领域:数学,物理,化学和代码。这些域问题需要准确的逻辑减少和特定域的应用,从而为MLLM提供复杂而多样的打喷嚏术语。诊断细粒度的能力和绩效限制的探索:Emma对一般评分不满意,但为每个学科中的特定技能提供了详细的分类(例如,数学中的“ 2D变换”,“ 3D空间仿真”,“物理学”中的“力量分析”,“现场模拟”。此设计允许S研究人员可以准确研究特定推理链接中模型的优势和缺失,并绘制模型功能的“细粒度图片”。该研究具有以下主要发现:一般绩效:即使是最先进的模型(例如Gemini-7.5-Pro-Exp-03-25)或O3/O4-Mini模型,这些模型也可以使视觉工具呼叫仍然落后于艾玛(Emma)20%以上的人类专家。在计算扩展或程序方法的情况下,该模型无法有效地弥合与人民的差距。思维链并不是灵丹妙药:尽管链条曲调正在思考影响某些开放资源模型。测试过程中计算扩展的影响不好:即使试验过程中的计算源通过增加候选答案的数量(例如大多数投票,最佳N,竞赛方法)扩大,也无法有效支付基本视觉推理能力中的模型缺陷。视觉推理是主瓶颈部:错误分析表明,MLLM通常在需要准确的空间仿真,多键视觉推理以及视觉和文本信息的集成的活动中失败,而LAIT则是视觉帮助可以极大地简化路径的问题 - 解决路径。它进一步强调了开发一种新机制,以深刻融合视觉和语言。数据集构建:严格的筛选和细粒分析艾玛构建过程经过精心设计,以确保它可以有效地评估深层多模式推理能力。 Data Source and Filter: Emma Contains 992 Questions obained from existing benchmarks (such as MathVision, Mathvista, Olympiadbench, MMMU, etc.) Through a strict filtering process (as shown in the figure above, filtering out problems that can be solved by text or "text + image Description" alone), and Has Manually constructed 1,796 brand new questions for a total of 2,788 questions in cooperation with experts in relevant fielDS。域域评估和技能:数学:包括AOF 2D更改,3D空间仿真,路径跟踪,多SKIP视觉对象计数,推理模式等。物理:包括3D现场仿真,推理图表,路径轨道,多SKIP视觉识别等以及基于目标图像(不提供原始图像),介绍了数据可视化的目标。反射分类:每个问题都有一个详细的技能标签,以允许对模型的不同功能进行深入分析。 MANU验证和质量控制:所有问题,尤其是新建的问题和分类标签,都是由现场专家严格评估或创建的,以确保质量,问题的相关性以及对多模式辩护能力的真实分析。最后,关于EMMA数据集数据的统计和分布的基本信息,如下所示:实验和结果:SOTA模型面临认真的试验。Arch团队在Emma审查了10个SOTA MLLM,包括开放资源(例如Qwen2-Vl,Llava-onevision,InternVL2)和封闭的资源(例如GPT-4O,Claude 3.5 Sonnet,Gemini 2.0 2.0 Flash/Thinking/Thinking,O1)。总体表现不佳:在Emma中,所有模型在人类专家中的空间都不好,其限制在解决了多模式理解的复杂活动中的局限性。 COT效应:对于封闭的资源模型,COT信号通常会提高性能;但是对于开放的资源模型,COT可能导致性能恶化,这可能与模型无法有效地使用NA帮助的模型有关。在测试时很难造成缺点:尽管使用大多数投票,最佳N和冠军选择等技术可以在一定程度上提高绩效,但改善受到限制,远非足够的桥梁人类水平的差距。这表明只有越来越多的TE候选人XT COT在视觉推理步骤中很难为主要缺乏模型支付。错误分析:推理推理是错误类型的主要错误关键:数学部分和Emma-Mini代码中的O1模型错误评估表明,最高比例的视觉推理错误(52.83%)(52.83%),随后是感知错误(30.19%)(30.19%),而知识帐户的文本错误和缺乏知识的帐户不知情。这证明了视觉推理是主要的性能瓶颈。 Negative impact of cot on visually intensive tasks: although in tasks such as "language can assist reasoning" such as "multi-hop counting", we have seen that some closed-source models have improved performance with the assistance of cot, text cot can even negatively affect the performance of some models on tasks as "2d Transformation "that are highly dependent on visual simulation and spatial imagination, which prompts us to need new paradigms to improve visual厌恶。分析的示例:一个典型的错误情况是在判断磁场力的方向时,尽管模型(O1)知道应该使用“右手规则”,但在模仿拇指指向时是错误的,这是由于有限的视觉空间想象力所致。在未来的角度:跨模式智能艾玛基准系统系统地宣布了当前的多模式智能在跨越语言和视觉间隔时面临的特定挑战和瓶颈,并且通过设计出色的工作,它可以阐明实用的方向和关键点,以开发下一代跨模型模型。 Bagaman ang kasalukuyang模型多模式gumawa ng makabuluhang pag-unlad,nahaharap pa rin ito sa dalawang mahahalagang teknikang teknikang na bottlenecks:在Teksto,Mahirap Para SA多模型upang ganapna mapagtanto ang tumpak na pagkakahanay在Pagsasanib ng mga tampok na modal sa yugto ng预训练,na sineseryoso ang kasunod kasunod na pagganap na pagganap ng modelo sa sa推断阶段;另一方面,当前模型通常是无效的,并且很难与视觉状态的跨模式和实时更新实现真正的接触。因此,多模式智能趋势的未来发展不可避免地从现有的语言识别模型转变为以更深层的方式进行合作的更深入的动态模型。具体而言,下一代模型不仅需要具有推理行动的能力(例如调用图像编辑工具来帮助理性),而且还需要实现视觉状态和交叉模式反馈的积极更新,从而在下一个语言 - 视觉交互式推理中很好地驾驶。艾玛(Emma)揭示的具体挑战和路径将帮助研究人员更清楚地设计新的多模型模型结构和技术实践,这LY在更高级别上促进跨模式智能。
“三点电荷 + q,-2q和 + 3q平等放置。哪个向量最能描述作用在 + Q电荷上的净功率的方向?”解决此问题时,我们可以通过绘制力量分析的草图来轻松解决它。但是,即使是GPT-4O等先进的多模式大型语言模型,也可能会错误地判断拒绝的方向:在理解“同性拒绝”的基本物理原理时(例如,错误地判断否定 +3Q的 +3Q方向为 +Q的 +Q作为下部右侧而不是右上左侧)。看似简单的物理问题揭示了多模型模型的“致命缺陷”:当前的MLLM仍然无法产生复杂的多模式推理,需要将深度透视和文本整合在一起!艾玛(Emma)的基准发射了新研究,就像是“恶魔镜”,表明即使是领先的MLLM也有重大的缺点。目前,这项研究已被接受为ICML 2025聚光灯,并且代码数据完全O笔资源!标题:MLLM可以引起多模式吗?艾玛:改进的多模式推理基准纸链接: https://www.arxiv.org/pdf/2501.054444444444444444444444444444444444444444444444444444444444444444444444444444; “ https://huggingface.co/datasets/luckychao/emma部门:孙子Yat-sen大学电子科学技术大学,华盛顿大学,微软大学,中文大学,目前具有EMMA中的许多模型/方法,在上面证明,它已被证明是多种研究和研究的能力,并且已经发现了研究的模型。 O3/O4-Mini模型可以在人类专家身后捕获20%以上的人!ual thinking and spatial simulation" to efficiently find the path-solving path. In sharp contrast, models (like the O3) rely on detailed, structured text steps for reasoning. This difference highlights that current MLLMs tend to use their strong language logic capabilities to process when processing multimodal information, nGorgeously show like human, visual centered on intuitive perspective and flexible and excellent problem solving techniques. Emma: In-depth consideration有机地结合文本和图像信息和进行音乐会推理的多模式的理论是人类智力的基本能力,如果多模式模型真正具有这种深层的水平,那么多模型的多模式推理能力仍然缺乏系统的限制和唯一的用文字。视觉感知“而不是” visual reasoning" to solve the problem. Difficult to comprehensively measure model's ability to combine visual and linguistic imFormation in complex activities, so it is impossible to effectively evaluate the true understanding of multimodal and reasoning level. To meet this challenge, researchers suggested Emma, an enhanced benchmark designed to review native multimodal reasoning for MLLMs in four major fields: mathematics, physics, chemistry and code, as shown in the figure below. EMMA activities require advanced cross-modal reasoning, which cannot be solved by thinking independently in a single mode, providing a more stringent and comprehensive "touchstone" for MLLMS reasoning capabilities. Emma is not just a new review, this is a carefully designed set of "testing questions" aimed at comprehensively reviewing the capabilities of MLLMs in the following aspects: real multimodal fusIon: Emma's main criterion is to test if the model can perform "true"多模式推理应通过视觉信息(例如图表,示意图,化学结构,代码纪念)和文本信息(问题描述,逻辑条件)深入解决问题,从而测试模型无缝移动和在不同模式之间进行深层集成的能力。严重的跨学科挑战:为了完成对将军的一般能力的分析,艾玛涵盖了科学和工程的四个主要领域:数学,物理,化学和代码。这些域问题需要准确的逻辑减少和特定域的应用,从而为MLLM提供复杂而多样的打喷嚏术语。诊断细粒度的能力和绩效限制的探索:Emma对一般评分不满意,但为每个学科中的特定技能提供了详细的分类(例如,数学中的“ 2D变换”,“ 3D空间仿真”,“物理学”中的“力量分析”,“现场模拟”。此设计允许S研究人员可以准确研究特定推理链接中模型的优势和缺失,并绘制模型功能的“细粒度图片”。该研究具有以下主要发现:一般绩效:即使是最先进的模型(例如Gemini-7.5-Pro-Exp-03-25)或O3/O4-Mini模型,这些模型也可以使视觉工具呼叫仍然落后于艾玛(Emma)20%以上的人类专家。在计算扩展或程序方法的情况下,该模型无法有效地弥合与人民的差距。思维链并不是灵丹妙药:尽管链条曲调正在思考影响某些开放资源模型。测试过程中计算扩展的影响不好:即使试验过程中的计算源通过增加候选答案的数量(例如大多数投票,最佳N,竞赛方法)扩大,也无法有效支付基本视觉推理能力中的模型缺陷。视觉推理是主瓶颈部:错误分析表明,MLLM通常在需要准确的空间仿真,多键视觉推理以及视觉和文本信息的集成的活动中失败,而LAIT则是视觉帮助可以极大地简化路径的问题 - 解决路径。它进一步强调了开发一种新机制,以深刻融合视觉和语言。数据集构建:严格的筛选和细粒分析艾玛构建过程经过精心设计,以确保它可以有效地评估深层多模式推理能力。 Data Source and Filter: Emma Contains 992 Questions obained from existing benchmarks (such as MathVision, Mathvista, Olympiadbench, MMMU, etc.) Through a strict filtering process (as shown in the figure above, filtering out problems that can be solved by text or "text + image Description" alone), and Has Manually constructed 1,796 brand new questions for a total of 2,788 questions in cooperation with experts in relevant fielDS。域域评估和技能:数学:包括AOF 2D更改,3D空间仿真,路径跟踪,多SKIP视觉对象计数,推理模式等。物理:包括3D现场仿真,推理图表,路径轨道,多SKIP视觉识别等以及基于目标图像(不提供原始图像),介绍了数据可视化的目标。反射分类:每个问题都有一个详细的技能标签,以允许对模型的不同功能进行深入分析。 MANU验证和质量控制:所有问题,尤其是新建的问题和分类标签,都是由现场专家严格评估或创建的,以确保质量,问题的相关性以及对多模式辩护能力的真实分析。最后,关于EMMA数据集数据的统计和分布的基本信息,如下所示:实验和结果:SOTA模型面临认真的试验。Arch团队在Emma审查了10个SOTA MLLM,包括开放资源(例如Qwen2-Vl,Llava-onevision,InternVL2)和封闭的资源(例如GPT-4O,Claude 3.5 Sonnet,Gemini 2.0 2.0 Flash/Thinking/Thinking,O1)。总体表现不佳:在Emma中,所有模型在人类专家中的空间都不好,其限制在解决了多模式理解的复杂活动中的局限性。 COT效应:对于封闭的资源模型,COT信号通常会提高性能;但是对于开放的资源模型,COT可能导致性能恶化,这可能与模型无法有效地使用NA帮助的模型有关。在测试时很难造成缺点:尽管使用大多数投票,最佳N和冠军选择等技术可以在一定程度上提高绩效,但改善受到限制,远非足够的桥梁人类水平的差距。这表明只有越来越多的TE候选人XT COT在视觉推理步骤中很难为主要缺乏模型支付。错误分析:推理推理是错误类型的主要错误关键:数学部分和Emma-Mini代码中的O1模型错误评估表明,最高比例的视觉推理错误(52.83%)(52.83%),随后是感知错误(30.19%)(30.19%),而知识帐户的文本错误和缺乏知识的帐户不知情。这证明了视觉推理是主要的性能瓶颈。 Negative impact of cot on visually intensive tasks: although in tasks such as "language can assist reasoning" such as "multi-hop counting", we have seen that some closed-source models have improved performance with the assistance of cot, text cot can even negatively affect the performance of some models on tasks as "2d Transformation "that are highly dependent on visual simulation and spatial imagination, which prompts us to need new paradigms to improve visual厌恶。分析的示例:一个典型的错误情况是在判断磁场力的方向时,尽管模型(O1)知道应该使用“右手规则”,但在模仿拇指指向时是错误的,这是由于有限的视觉空间想象力所致。在未来的角度:跨模式智能艾玛基准系统系统地宣布了当前的多模式智能在跨越语言和视觉间隔时面临的特定挑战和瓶颈,并且通过设计出色的工作,它可以阐明实用的方向和关键点,以开发下一代跨模型模型。 Bagaman ang kasalukuyang模型多模式gumawa ng makabuluhang pag-unlad,nahaharap pa rin ito sa dalawang mahahalagang teknikang teknikang na bottlenecks:在Teksto,Mahirap Para SA多模型upang ganapna mapagtanto ang tumpak na pagkakahanay在Pagsasanib ng mga tampok na modal sa yugto ng预训练,na sineseryoso ang kasunod kasunod na pagganap na pagganap ng modelo sa sa推断阶段;另一方面,当前模型通常是无效的,并且很难与视觉状态的跨模式和实时更新实现真正的接触。因此,多模式智能趋势的未来发展不可避免地从现有的语言识别模型转变为以更深层的方式进行合作的更深入的动态模型。具体而言,下一代模型不仅需要具有推理行动的能力(例如调用图像编辑工具来帮助理性),而且还需要实现视觉状态和交叉模式反馈的积极更新,从而在下一个语言 - 视觉交互式推理中很好地驾驶。艾玛(Emma)揭示的具体挑战和路径将帮助研究人员更清楚地设计新的多模型模型结构和技术实践,这LY在更高级别上促进跨模式智能。
|
